
The human mind and Artificial Intelligence are still learning to coexist, with the full potential and harmony of this exciting symbiosis and ubiquitous connectivity yet to be unfolded. Though AI is arguably still in its nascent stages, this technology has been permeating our lives for quite some time. Natural Language Processing, or NLP technology, is one of the most exciting components of AI and has been improving our online experience to an extent that most of us aren’t entirely aware of.
When we use Google Translate, Search Autocomplete, email filters, smart assistants, and numerous similar applications, we are actually harvesting the power of Natural Language Processing solutions.
What is Natural Language Processing & How Does It Work?
One of the critical (and quite challenging) steps toward the aforementioned symbiosis is AI’s ability to listen, speak, write, and ultimately understand human language, and – perhaps most importantly – the main intent behind it.
Natural Language Processing, though still evolving, is a form of AI that utilizes a subfield of linguistics and computational processes to make the interaction between software and human language as seamless as possible, with little to no chunks of meaning getting lost during the procedure.
The end result involves computers being capable of processing and analyzing large amounts of natural language data, and in so doing “understand” the content of the information being conveyed, including the wide spectrum of contextual nuances involved and the intent hidden within the structure of the human language. This enables Natural Language Processing solutions to extrapolate accurate information and glean actionable insights, as well as categorize and manage granular data.
One great use case example that we all utilize daily is an email spam filter. Platforms like Gmail use NLP technology to recognize, classify and filter your emails by analyzing the text and the contexts within the emails flowing through their servers in order to prevent spam messages from reaching your main inbox and ruining your day.
This brings us to:
Typical Applications of Natural Language Processing Solutions
Natural Language Processing algorithms and Machine Learning technologies have been successfully applied across multiple industries, wherein these solutions act as major catalysts for streamlining various convoluted and time-consuming processes. The industries that have evolved the most during recent years due to the use of NLP include:
- Healthcare (Electronic Medical Records systems)
- Pharmaceuticals (reading safety-relevant data within the unstructured text)
- Finance/Legal, FinTech, insurance (structured data analysis, chatbots, document processing, etc)
- Digital marketing and IT (raw data and KPI analyses, ad targeting, market insights, eCommerce, chatbots, UX, voice search, etc)
- E-Governance
- Education
…the list goes on. However, we will now quickly take a closer look at certain niche-based examples of Natural Language Processing solutions that we find particularly relevant, as they power modern businesses and help them grow and evolve faster.
Customer Service & User Experience
NLP has changed the game when it comes to UX and customer service. Not only does it improve a user’s online and offline journey via chatbots, predictive search, smart navigation, etc, it also automates these components from the service provider standpoint and renders operations much more streamlined and cost-efficient.
E-commerce and Sales Support
The global-scale events of 2020 created an evident boom in online shopping, which probably wouldn’t have been entirely possible without the use of NLP. Natural Language Processing enables machines to analyze user behavior when a visitor searches and purchases products/services, thus providing valuable insight to service providers on how their audience is interacting with their systems. This type of interaction allows eCommerce businesses to create an improved customer journey for their users, while at the same time improving their own strategies and boosting leads/sales.
Reputation Management & Market Intelligence
ORM is an integral part of a brand’s online presence, as customer reviews can literally make or break a business or a career. NLP automates and improves this process through the use of content, keyword, sentiment, and context analysis of both structured and unstructured data. It can also help with market scanning with much more granular and cost-effective competitor research.
Text Platforms
Don’t tell my employees this, but a great deal of the sentences you are reading within this article have been auto-finished by Google Docs. Jokes aside, Natural Language Processing solutions are dramatically transforming our everyday communication via grammar and spell checkers like Grammarly, translation platforms like Google Translate, text improvement tools like InstaText, or the predictive text component present in most virtual keyboards our smartphones use.
Voice Automated Solutions & Smart Mobile Devices
NLP technology has made real-time interaction between humans and machines a reality, not just a far-fetched element used in sci-fi movies. It makes voice automated systems like Alexa, Siri, and Google Assistant possible by helping them decipher and process spoken language to improve both our workflows and everyday life experiences.
Digital Marketing
Natural Language Processing applications are deeply embedded in data-gathering and analysis-based operations present within the modern marketing landscape. They are used for improving ad targeting, gaining valuable market insights, improving digital presence, and other similar processes that drive this industry forward.
Employee Satisfaction
Artificial Intelligence, Natural Language Processing, and Machine Learning play a huge role in improving workflows, removing bottlenecks, and obviating the need for manual tasks within business operations, including task automation and survey analytics. For example, HTEC has helped many clients like Great Place to Work and Quinyx utilize NLP to improve their management and build high-trust workplace environments, as well as drive success through employee motivation.
HTEC EXPERIENCE – Making sense out of textual data
The most common and basic problem in NLP is understanding the semantics behind the content. Given a document, a paragraph, a comment – what does it mean, what does it refer to, and which topics does it cover? Extracting the meaning from a text is a powerful tool for understanding the behavior of those behind it and the author’s intents and interests, as well as for building a context around the users and predicting their future choices. But …
How to catch the meaning?
Before answering that question, another one needs to be answered first, namely: How to define the meaning? Text is made of words, and the way the human mind works is by carefully choosing which words to use to describe a particular phenomenon, combining specific words into phrases for specific topics, placing them into a particular order to make a point, and doing all that based on experience. The words, the phrases, and the order define the meaning. Extracting the words and phrases, and understanding their relations, is how meaning can be inferred. Sounds simple, as it’s exactly how our minds work, but how to mimic human reasoning?
Starting simple with statistics
The simplest method of extracting the meaning from a text is statistics-based. The final goal behind it is to create a representation of the text with the most important words and phrases describing it. Two challenges can be identified: the first is to extract the words and phrases, and the second is to score their importance. This class of statistics-based methods relies on word counting while neglecting the order and mutual relation of the words, except when finding phrases. A text is modeled as a bag of words – a set of unrelated entities in the same group/bag. One of the most popular counting techniques is the tf-idf method. Each word in a document is given a tf-idf score which is a product of two quantities – tf and idf:
- Term frequency (tf) – number of occurrences of the word in a single document,
- Inverse document frequency (idf) – how frequent is the word in (some) corpus of documents. This is a measure of the specificity of the word for the entire corpus.
The most important words are the most frequently occurring ones, but also the most specific ones. The specificity part of the score serves as a filter that removes common words i.e. “say”, “people”, “have”, etc.
Tf-idf-based methods are still the most popular approaches for document indexing used for search engines, such as Elasticsearch and Solr. They produce interpretable results, are computationally inexpensive, and work (surprisingly) well for long texts. On the other hand, a significant “part” of the meaning lies in the relation between a word and its neighborhood, which is neglected in the statistical model. This drawback is heavily manifested in the analysis of short documents. One method of deducing interword relations is the introduction of phrases (collocations) – a group of words that tend to often appear together. Although phrases can boost the quality of statistical models, they still don’t solve the main problem in a statistical family of approaches: i.e. the lack of semantics.
Being more insightful with semantics
Semantics-based models take into account the relations between words in a text in different contexts. They are trained on a large amount of mostly unlabeled, textual data, and are known as self-supervised models. Unlike statistical approaches, these models don’t work in the original word space, but transform human-understandable words into machine-understandable numbers, moving them into high-dimensional vector space.
One of the first, and probably the most well-known model, is word2vec, which projects each word into a numerical vector. Based on the word’s neighborhood, the position of the corresponding vector is determined to preserve and reflect the semantics of the word by preserving the original context.
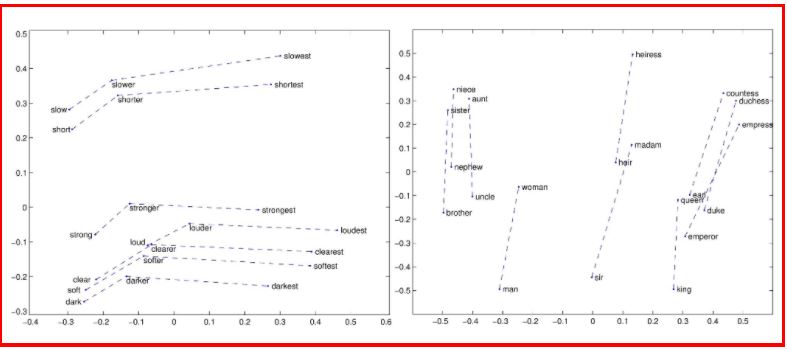
Figure 1. Word2vec; taken from https://ruder.io/secret-word2vec/
The position of the word-vector is what represents the meaning behind the word. Thus, the vector space can be comprehended as a semantic space. However, word-based vector models suffer from one major drawback: one word = one position. As a word’s meaning heavily depends on the context, e.g. “I saw what happened” vs “This saw is sharp”, it is logical to expect different positions for the same word in a vector space for different ways of using the word (i.e. different contexts).
The introduction of the attention mechanism in 2017 created a new class of models named transformers, which revolutionized NLP. Machine translation, named-entity recognition, conversational systems, summarization and sequence similarity are some of the processes that were significantly improved with the new models. One of the first and most well-known transformer models is Google’s BERT, published in 2018. Since then a plethora of transformer models have appeared. Unlike word2vec, these models give a meaning/position to a word based on its context. Consequently, sequences of texts, such as sentences and paragraphs, can be better represented in vector space than with the previous generation of vector models.

Figure 2. Contextualized embedding using BERT. Taken from http://jalammar.github.io/illustrated-bert/
The advantages of vectorization over tf-idf models are clear: semantics originating from interword relations are (at least partially) captured. On the other hand, these models are computationally heavy and still quite problematic dealing with longer texts. While the long-text problem will probably be solved in the future, computational complexity remains a major concern. Two recent massive transformer models, GPT-3 from OpenAI and Switch Transformer from Google, confirm this fact. GPT-3 has 175 billion parameters, while Switch Transformer has 1.6 trillion, which puts them beyond the reach of most individuals and organizations. If not addressed properly, this trend will cause the de-democratization of NLP.
Now that we know the meaning, how should we use it?
One of the recent problems our team has been working on concerns federated search – a technique of searching multiple data sources at once. Given a search term (query), the search engine should return a single list of ranked results from all the sources available. Numerous challenges arise from this scenario:
- Performance-related – How long will the search take when the number of sources increases significantly?
- Quality-related – How to guarantee the most relevant content is on top of the results list?
- Engagement-related – How to not produce too much content?
Having an evaluation of the relevance of each data source for a given query before sources are queried is one way of addressing those challenges. The relevance is expressed by a numerical value – relevance score – and it gives an estimate of the probability that a particular source contains resources of interest for a specific search. This information brings multiple benefits:
- Speedup and cost reduction – not all sources need to be searched, only those with high relevance;
- Improved ranking – relevance scores could be used to rank results coming from more relevant sources higher.
To know if a source is relevant to a query, there needs to be an understanding of the content provided by the particular source. Or in other words, we need to know the meaning of the source. By knowing the meaning of the source on one hand, and the meaning of the query on the other, inferring source relevance for the query comes down to measuring the similarity between the two meanings.
A single source of data can be observed as one big data corpus. Each source is specific in terms of topics covered, types of resources, frequency of updating the content, etc. So, understanding the source is far more complex than only inferring the meaning of a text. To make the challenge even harder, such sources are usually restricted in terms of access, making it impossible to know about every resource available. The first challenge in making a data source understandable is building a representation of that source that is specific enough to infer the correct meaning from it, while at the same time diverse enough to cover all the topics and categories. One way of doing that is to collect a sample of representative documents from a source. But how to know when a sample is representative? Fortunately, there are a lot of statistical methods that can be used to measure the similarity between two samples, such as Jensen-Shannon divergence. By iteratively collecting resources from a source and adding them to a previously collected sample, such methods can be used to measure if the two consecutive samples are similar enough to be considered almost the same. When that condition gets satisfied, a sample can be considered representative.
With a sample ready, any of the aforementioned methods can be used to understand the source. To demonstrate the models in action, the following publicly available datasets will be used:
- Machine learning dataset – a subset of 31,000+ arxiv articles on ML subject, from Kaggle
- News dataset – a set of 143,000 articles from 15 American publishers covering the period from 2014 to 2016, also from Kaggle
- Medical dataset – a subset of around 5,000 PubMed abstracts from Kaggle
Figure 3 illustrates the representations of these sources.
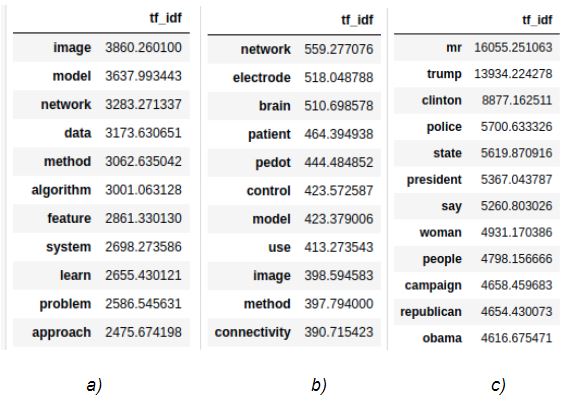
Figure 3: Source representations examples: a) Machine learning dataset, b) Medical dataset, c) News dataset
It’s noticeable how the specificity of the sources is maintained with the most frequent terms identified per source. Such representations are used as inputs for building statistical and semantic models for scoring the relevancy. Statistical models calculate relevance scores for each <term, source> pair, and the relevance score for the entire query is represented as a normalized sum of scores of individual terms for each source. In the semantic model, document texts are summarized and embedded into 512-dimensional vectors, along with the user’s query. The relevance score is the normalized value of mean similarity scores of the top N most similar documents to query from each source. Figure 4 illustrates a statistical model of precalculated scores for all the terms in the sources’ representations. It can be seen that there’s no clear separation between the relevancy of terms for different sources. Terms such as computerized, acceptability, career, etc, are relevant for multiple sources but to a different extent.
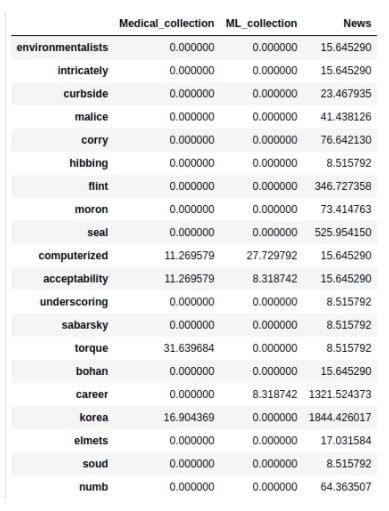
Figure 4. Statistical model example
In case of semantic relevance models, such as the one shown in Figure 5, it’s not that easy to understand the concept of relevancy. We’re not working with terms anymore, but with numerical representations of summarized resources found in sources. By simply looking at the model, there’s no way we could understand anything in it.

Figure 5. Semantic model example
Let’s see how they perform when it comes to real-life query examples and scoring their relevance. In Figures 6 and 7, the results of statistical and semantic models, along with the ensemble (combination) of both, applied to the queries ‘state of the art machine learning algorithms’ and ‘books exploring a technology that could transform humanity’ are presented respectively. The news collection source has the highest number of very long, heterogeneous documents, therefore most of the terms in the statistical model have the highest values for this source. In the bar plots shown below, for both queries statistical model scores News collection and ML collection with much higher scores than Medical collection; terms such as ‘machine’, ‘learning’, ‘algorithm’ are very common in ML_collection (circled in red in Figure 8) and ‘book’, ‘technology’ and ‘humanity’ are more common and important in News collection source than in other two sources of documents (rounded in green in Figure 8). The semantic model, as expected, scores ML collection with the highest relevance score for both queries, almost dropping out News collection for the state of the art machine learning algorithms. In the ensemble, the results of both models are taken into account; still, ML collection delivers the highest score, but News collection and Medical collection sources are also given negligible relevancy scores.
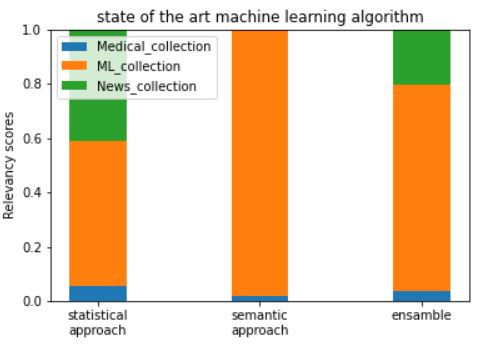
Figure 6. Example query: state of the art machine learning algorithm
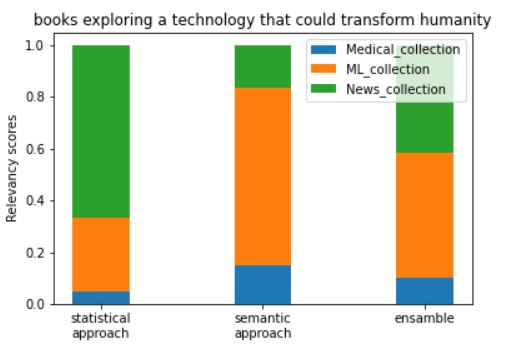
Figure 7. Example query: books exploring a technology that could transform humanity
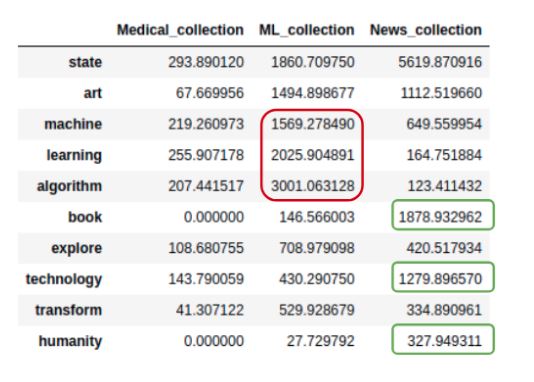
Figure 8. Query terms tf-idf
What’s Next Within the NLP Technology & Landscape?
Natural Language Processing has been rapidly evolving over the last couple of years, both in theory and practical utilization. Though the technology is merely at its initial stages of development, the utilization possibilities are endless.
When you throw deep learning into the equation and the increasingly improving scalability and robustness of the aforementioned systems, the future benefits that businesses are expected to reap are staggering, especially within the areas of operational management, customer service, business and market intelligence, digital marketing, healthcare, etc. By reducing the need for expensive data scientists, the operational costs go down substantially, while process efficiency skyrockets.
With recent reports stating that the NLP market is projected to reach $22.3 billion by 2025, and with numerous new paths and applications opening up for this industry, we are certain that NLP technology will continue to significantly improve our experiences, both online and offline, for years and decades to come.





